I used NSGA-II to run multi-objective hyperparameter optimisation over an LLM, balancing validation accuracy against the number of trainable parameters. The resulting Pareto front shows the trade-off:
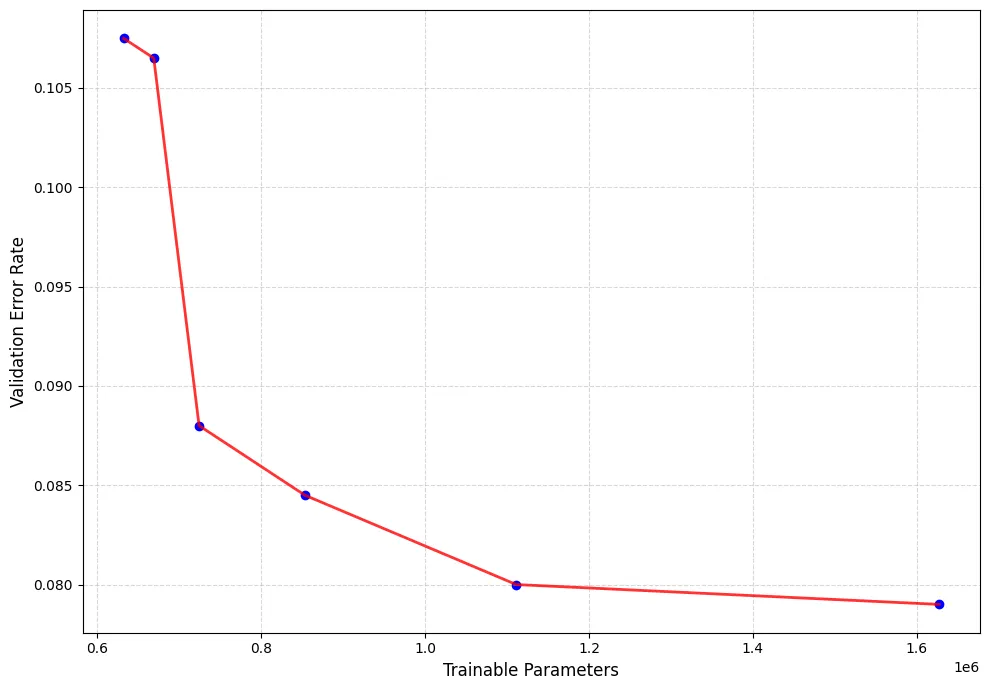
The chosen configuration cuts trainable parameters by 55.5% while holding validation accuracy level with the full model.
Finding a cheaper LoRA configuration with NSGA-II
This multi-objective hyperparameter search found a LoRA configuration running at roughly 45% of the size of the peak model while maintaining 99% of its accuracy.
The full setup can be found on my github or ![]()
Context
This project was part of a four-person group coursework assignment at the University of Surrey. The wider project compared several different tuning algorithms. The work shown here is my specific contribution. It is a multi-objective extension using NSGA-II to map the trade-off between model size and validation accuracy.
Why it matters
Standard single-objective searches only look for the highest validation accuracy. This completely ignores the reality of deployment costs. A model with more trainable parameters needs more GPU memory, requires more storage, and runs slower at inference.
What I did
I set up the search to minimise both the error rate and the number of trainable parameters at the same time. The output is a Pareto front, which is a set of configurations where you cannot improve one goal without sacrificing the other. The pipeline fine-tunes DistilBERT on the Emotion dataset using LoRA while DEAP’s NSGA-II algorithm explores six hyperparameters (learning rate, warmup, rank, alpha, dropout, and target modules).
Results
The search revealed two clear insights about parameter efficiency. First, adapting the feedforward layers buys the most accuracy, as every solution above 90% targets both attention and feedforward modules. Second, LoRA rank has sharp diminishing returns, so doubling the rank from 8 to 16 adds over 500k parameters for a negligible 0.1% accuracy gain. The best configuration for actual deployment is the knee point of the curve. This solution achieves 91.2% accuracy with only 724,230 parameters. A standard single-objective search would have discarded this option, but it is the smarter choice for a memory-constrained environment.
Reflection
If I were to continue this work, I would run the search with a larger population size over more generations. I would also apply this same multi-objective approach to a much larger base model where memory constraints are tighter.
Links and tools
• GitHub Repository: nsga-II_hyperparameter_optimisation
• Tech Stack: Python, PyTorch, Hugging Face Transformers, PEFT, Datasets, DEAP, scikit-learn, Matplotlib